Lessons learned running AWS Cloud Map service discovery for EC2 instances
CommentsAt Voxnest - the company behind Spreaker, Dynamo and BlogTalkRadio - we’re doing an extensive usage of Kubernetes and Serverless solutions.
These technologies cover most of our needs, but we still have few specific use cases where self-managed clusters of EC2 instances are the best trade-off.
Introducing Cloud Map for service discovery
We recently had the need to expose an application running on a self-managed cluster of EC2 instances through a service discovery, and we started using Cloud Map.
Cloud Map allows you to define a logical entity called “service” which keeps a pool of healthy endpoints called “instances”. Multiple services are organized in “namespaces”.
The naming “instance” - in relation to a Cloud Map service - may you erroneously think you can just register EC2 instances to a service, but you can actually register any IP:PORT endpoint wherever it runs, whether it’s an EC2 instance, an ECS task, a server outside AWS or whatever.
Cloud Map offers an API to register and deregister an instance from a service, supports health checking, and allows to query the service instances via DNS or API.
We found Cloud Map simple yet effective for non complex setups, but at the same time we’ve learned a couple of failure scenarios you should be aware of:
- An unhealthy instance is registered to Cloud Map
- A terminated EC2 instance is not deregistered from Cloud Map
Failure scenario: an unhealthy instance is registered to Cloud Map
At the beginning of our experience with Cloud Map, we were assuming that when you register an instance to a Cloud Map service, the instance is added to the pool of healthy instances as soon as the first health check succeed. However, before going to production, we decided to run an extensive test to verify this assumption and we found out we were wrong.
Cloud Map supports two different types of health checks:
- Route 53 health check
- Custom health check
A Route 53 health check requires the service to be publicly exposed via HTTP(S) or TCP protocol. It’s fully managed and straightforward to use, and it’s usually a no-brainer choice for publicly exposed services.
A custom health check, on the contrary, is self-managed: it’s your responsability to run health checks against the instances registered to the service discovery and keep their status updated calling the UpdateInstanceCustomHealthStatus API. This allows you to monitor instances on private networks or to run the health check on a custom protocol.
An health check status can be HEALTHY or UNHEALTHY. As you can guess, an instance is removed from the pool of healthy instances when its status is UNHEALTHY and added back to the pool once HEALTHY.
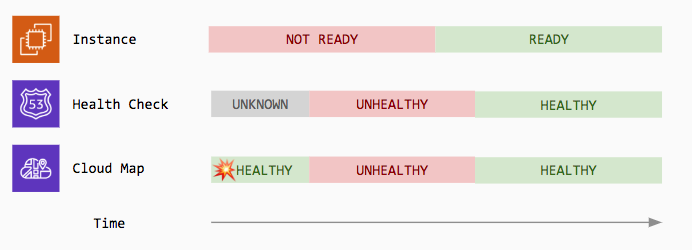
However, a Route 53 health check may also have a third state UNKNOWN. The unknown state is the initial state of an health check before the first check runs. Contrary to our initial assumption, our experiments showed that when a Route 53 health check is in the UNKNOWN state, its instance is added to the pool of healthy instances.
| Health Check Status | Route 53 | Custom |
|---|---|---|
HEALTHY |
✅ | ✅ |
UNHEALTHY |
✅ | ✅ |
UNKNOWN |
✅ | - |
This opens to following failure scenario:
- An application is started on a new instance, but it’s not ready to serve traffic yet
- The instance is added to the service discovery and its Route 53 health check status is
UNKNOWN - Production traffic starts getting routed to the new instance, but requests fail because not ready
- The instance health check fails and the instance is removed from the pool of healthy instances
- The application startup completes and the instance is now ready to serve traffic
- The instance health check succeeds and the instance is added to the pool of healthy instances
How to protect from this failure scenario
To protect from this failure scenario, you should register an instance to the Cloud Map service with Route 53 health check only once the instance is ready to serve traffic.
If you’re using custom health checks, the RegisterInstance API supports AWS_INIT_HEALTH_STATUS attribute to specify the initial status of the custom health check, HEALTHY or UNHEALTHY (defaults to HEALTHY), but unfortunately this attribute has no effect if you’re using Route 53 health checks.
Failure scenario: a terminated EC2 instance is not deregistered from Cloud Map
Looking at examples of integration between Cloud Map and EC2 instances, we’ve seen that a common practice is to have the EC2 instance itself registering to the Cloud Map service (via API) once the application is ready to serve traffic and deregister it at application / instance shutdown.
This approach works as far as the shutdown hook is reliable and guaranteed to be executed in any condition. However, if it’s the responsability of the EC2 instance to deregister itself, you may miss to deregister it in case of EC2 instance failure, or any temporary error (ie. networking issue) that may occur at shutdown, or a bug in your shutdown script.
At first, we thought the health check would have protected us from this failure scenario. In the unlikely event the EC2 instance fail and the shutdown script is not called, the Cloud Map service health check will fail and will remove the instance from the pool of healthy endpoints.
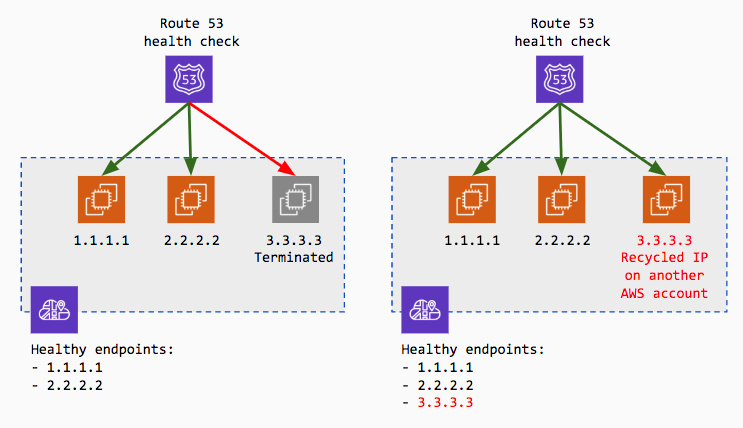
Despite this is true, we experienced a way worse failure scenario following up the condition we’ve just described. The public IP address of the terminated EC2 instance - which is still erroneously registered to the Cloud Map service - is recycled by AWS and assigned to a new EC2 instance not belonging to our AWS account.
Unlikely, the new third party EC2 instance - with the recycled IP assigned - was running an HTTP server on the standard port, the Route 53 health check began succeeding and this “spurious” EC2 instance IP has been added back to the pool of healthy endpoints, despite was not running our own application.
How to protect from this failure scenario
This was not a Cloud Map failure. This was a failure in how we initially integrated with Cloud Map.
There are multiple ways to better integrate without hitting this issue. One of them is to deregister the EC2 instance in a Lambda triggered by an EC2 event (you may want to introduce SQS + a deadletter queue to protect from temporary failures while deregistering).
Another may be implementing an external controller to register and deregister the instance, without having to run it from the EC2 instance itself. In this case you may also need to run health checks before registering the instance, to avoid to fall in the case an unhealthy instance is registered.
The solution we came up with is to keep the register and deregister in the instance itself, but to also run an external controller to remove terminated EC2 instances from the Cloud Map service, with a tiny application we released open source:
You may also be interested in ...
- Growing an AWS EBS RAID 0 array, increasing volumes size
- Announcements during AWS re:invent 2018 - Andy Jassy Keynote
- Install Spark JobServer on AWS EMR
- AWS re:invent 2017 annoucements
Upcoming conferences
| Incontro DevOps 2020 |
 Virtual
Virtual
|
22 October 2020 |
|---|